At the end of July, Greg Kossakowski and I shipped Unpitched, an AI-powered tool that helps startup founders conduct better customer interviews. It took us ~5 weeks to ship. I wouldn’t consider this particularly fast if it weren’t for the fact that I was simultaneously developing two other apps.
In the past two months, how I code products has evolved significantly. At the end of June, at the AI Tinkerers meetup in Warsaw, Greg and I presented the workflow I came up with and used to build most of Unpitched. The following diagram gives you the big picture, and I’ll walk you through the details in the next section.

However, we didn’t tell the full story. At the time of the presentation, my workflow had already evolved significantly thanks to Claude Code, a command-line-based coding agent from Anthropic. I wasn’t ready to speak about it publicly, but it was an inflection point for me. In Cursor, I worked on one task, maybe two at any given time. With Claude Code, I could have 3-4 agents working on different tasks simultaneously, some running for hours, with outputs better than those in Cursor.
The approach I’m describing today isn’t for everyone. It’s specifically designed for developers who already understand code architecture, patterns, and quality. I deliberately didn’t title this How I Vibe Code These Days because there’s a fundamental difference between vibe-coding and AI-augmented engineering. My goal is to learn ways to scale my engineering capabilities. I keep asking myself: “Is what I’m doing something I could automate?” and “Is it possible to articulate what I expect so an agent could handle it independently?”
This is also a pursuit of speed, but not the kind that sacrifices quality. I believe there are two ways to go fast. First, you can fail fast by iterating quickly—the upside is learning speed, but the downside is usually poor codebase quality, which slows you down as development continues. Second, you can use your brain, skills, and experience to think about laying the right foundation first. I’ve tried both approaches, and based on my own experience and observing others, despite the initial slowdown with the latter approach, you end up faster and more agile in the long run.
The workflow I’ll describe embodies this second philosophy—building robust foundations that enable sustainable speed through AI augmentation.
This blog post describes my workflow as of early August, before Opus 4.1, Cursor CLI and GPT-5 came out. While I won’t dive into technical implementation details here, this post is primarily structured for technical people—whether you’re already using tools like Cursor, experimenting with AI coding, or want to understand how advanced AI-augmented development actually works in practice. For non-technical readers curious about the future of professional software development, this should give you insight into where things are heading.
My Original Workflow in Cursor
To explain my current approach, let’s start with the version Greg and I used and presented at AI Tinkerers in June. Back then, I used Cursor as my IDE (code editor) and had a preference for Claude Sonnet family models for most coding tasks.
My workflow is based on the following cycle:
- Create a plan using documentation as context.
- Work on the plan.
- Review code and implementation.
- Convert the plan and implementation into documentation.
Its value comes from the compounding effect of producing and using growing documentation as context.
Imagine you wanted to build a confirmation dialog for deleting critical resources in your app. The pattern nowadays is to type in some text to confirm you’re 100% sure you want to delete it.
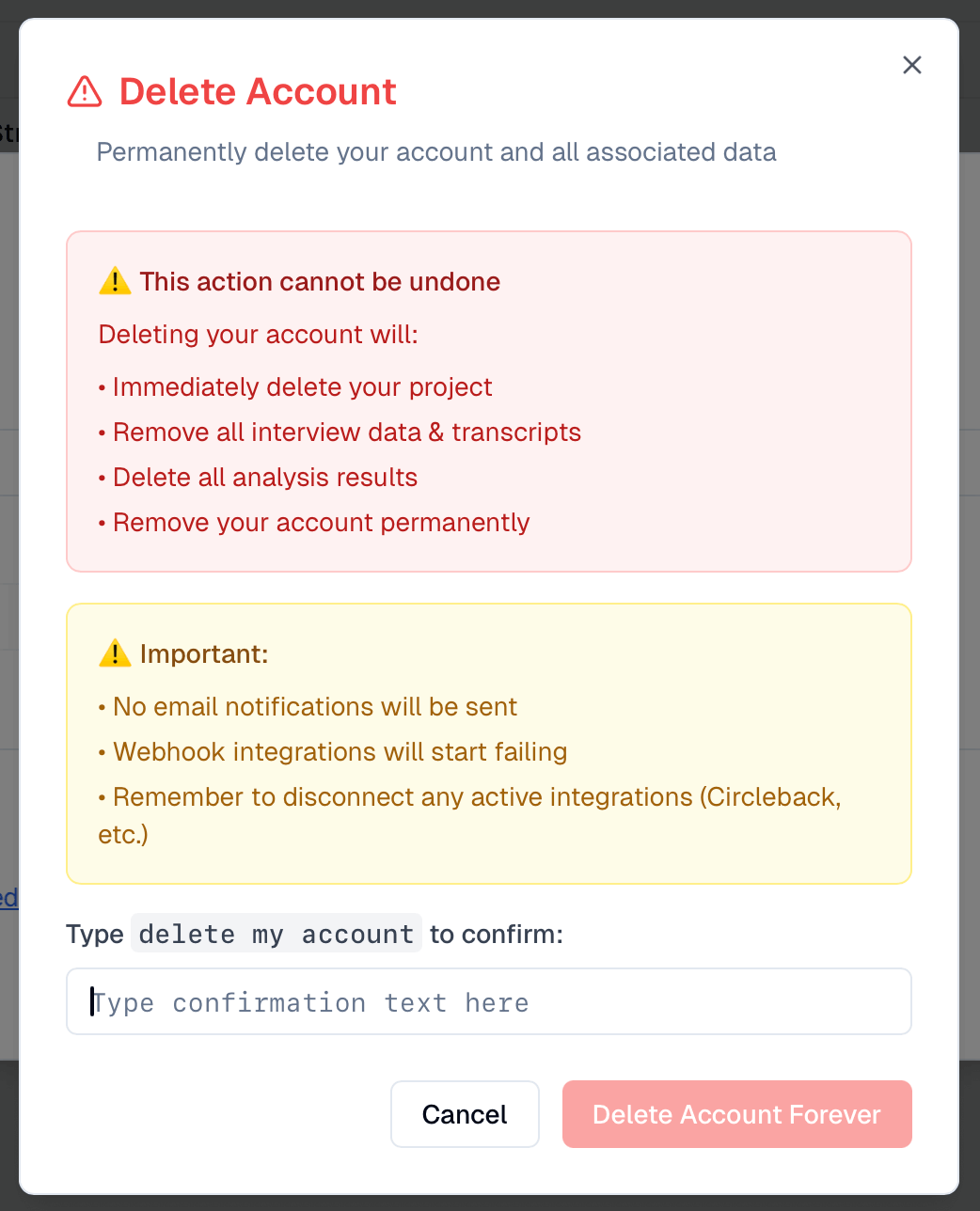
You could simply open Cursor and type Build a confirmation dialog for deleting a user account. Please add an input to type in some text to confirm deletion. Then, have the agent code some version and iterate by giving feedback until you get what you want.
Or you could spend 20 minutes refining what you want and have it accomplish the task in almost one-shot fashion (getting the expected result using a single prompt or plan). Many of us call it planning, but the process is more akin to… specifying. Finally, you’d convert your work into documentation to be reused later in other prompts.
Here’s a more detailed step-by-step overview of the process:
- Prompt the model to come up with a plan on how to build a feature or refactor code. Explain where the scope ends.
- Provide it with existing documentation, code snippets, examples.
- Ask it to clarify ambiguities until both you and the model are satisfied.
- Ask it to save the plan as a .md file, read it, review it, and ask for changes. Do not skip this step.
- Clear context.
- Ask the agent to implement a single phase or task from the plan.
- Review the code, test the functionality, ask the agent for necessary changes.
- Ask it to update the plan based on progress or changes.
- If not finished, go back to step 5: Clear context, implement next task…
- Once finished, ask it to convert the plan and implementation into documentation.
- Git commit and move onto the next thing.
Here are my tips for getting the most out of this workflow:
- In Cursor, choose the Agent mode for planning and pick the Claude Sonnet 4 (Thinking) model. You could opt for Opus or OpenAI o3 reasoning models for harder tasks. I’ve had the most success with Anthropic models.
- Ask the agent not to code unless specifically instructed. In Cursor’s Ask mode, the agent can’t access MCP tools or edit files. Simply run it in Agent mode but constrain it by telling it not to code.
- When writing the first prompt:
- Provide the agent with a thorough description of what you want, but don’t overcomplicate things initially. If you don’t type fast, use Aqua/Wispr Flow or another STT app. Some people have stopped typing entirely and rely on voice instead. In my case, typing is more than just a mechanical activity—it triggers a thought process and gets me into the zone. But I do use voice pretty much daily, for example to write tickets in Linear.
- Provide the model with robust context: include documentation, examples, code snippets, reference files, and library/framework documentation.
- Use text expansion (or text replacement on Mac) or Prompt Stash via Raycast for prompts you reuse frequently. Don’t waste time typing the same things repeatedly. For example, when I type
.askmeeon my Mac/iPhone, it automatically expands toBefore coding, clarify any ambiguities by asking questions. Prefix each question with a letter, prefix each suggested answer with a number so I can reference them easily. - Ask the model to ask you questions to clarify ambiguities before creating the plan. I use my text expansion to add this at the end of my message. Here’s what it looks like in practice:

Model asking clarification questions before creating a plan in Cursor - Once ready, ask the agent to save the plan as a file. I usually save it to the
./docs/plansdirectory. I don’t specify the name—it gets it right most of the time. - When creating the plan, Sonnet 4 and Opus tend to split tasks into phases, other models less so. I like this approach! However, I ask them to assign an ID to all tasks including subtasks. This makes it easier to specify what the agent should work on next.
- Always clear context when beginning work on a new phase or task.
- Ask the model to mark progress in the plan and update it with any changes that come up.
- Always review the code. This is very important. I’ll revisit this in a second.
- Models aren’t great at getting CSS (or Tailwind) right. It’s more efficient to spend one minute tweaking that padding yourself than iterating via a model.
- Commit changes after each phase, or at least commit everything before converting the plan into documentation. You’ll be able to go back to the original plan via git if necessary.
- I delete plans as I consider them less useful than good, precise, and up-to-date documentation.
- When creating documentation, ask the agent to:
- Cross-check the plan with what’s been implemented (this encourages the new agent, one with clear context, to familiarize itself with the implementation).
- Provide references to relevant files in the documentation.
- Provide code examples for how to code similar things in the future.
- Include and describe any principles or software patterns in use in the repo.
- List any relevant URLs, such as documentation that might be useful in the future.
- Save the doc in
./docs/<area>/<name-of-doc>.md.
- From time to time, I ask the model to analyze each piece of documentation against what’s implemented and update accordingly. About once every two weeks or so.
Now imagine that you’ve followed this workflow and documented the following functionality in your app: client and server-side validations, error-handling, UX patterns for notifications. If you followed this workflow, you’d end up with docs explaining how your codebase should grow in a sane, well-structured way. If you supply these docs as context, you can be almost sure you’ll end up with desired, high quality code.
Working this way had a huge impact on the reliability of agents working on my behalf. I typically spend anywhere from 5 to 40 minutes planning and specifying each feature/change. This process requires me to read the plan and verify proposed code and architecture to align my expectations with the model. It’s almost like an autopilot, but each autopilot needs to be told where it should be heading.
Code and Feature Reviews
Before jumping into how I work today, there’s something I want to discuss first. I mentioned it already, but it deserves highlighting once more.
You should be reviewing both the plan and code produced by agents. This is AI-augmented engineering, not AI-vibe-led engineering. Unless you’re working on a throwaway project or rapid prototype, you’ll quickly regret not reviewing code.
There are several reasons why you should do this, but I’ll give you the most important ones:
-
You are part of the equation
you_engineer * ai = 3x you. You need to use your engineering skills and experience to end up with the right code, patterns, code organization, technical choices, and product experience. You should have a good idea of what’s happening in the codebase and steer it in the right direction. It’s similar to what people get wrong about leadership and team empowerment.So many people I meet naively believe that the key to empowering product teams is simply to get management to back off, stop micromanaging, and give their product teams some space to do their jobs.
But as I’ve tried to explain many times, empowered product teams depend not on less leadership, but on better leadership.
AI-augmented programming doesn’t mean removing yourself from the process. It means you can focus on areas that create leverage, given that some parts of your work are being automated. In the end, the job of a great engineer isn’t writing code, but solving problems, coming up with innovations and creating value.
-
You need to understand how the model thinks. After about 4 weeks, you’ll start to anticipate what’s needed to keep outputs aligned with your expectations. This doesn’t mean lowering your standards—quite the opposite. By understanding AI’s limitations, you become better at organizing work and providing context. You need hands-on experience to develop these skills.
-
If you don’t review code, you’ll end up with AI slop. Eventually, you’ll spend time fighting the model instead of getting what you want. Code generated by AI might pollute its context, dooming your AI-augmented coding. You might also become someone who claims it’s not there yet. Yes, for some areas, AI agents aren’t ready at all. But in well-structured, documented environments with ubiquitous tech stacks, what these models can already achieve is mind-blowing.
If you’ve never coded before, you can probably tell that I put a lot of emphasis on prior engineering knowledge—and rightly so. These tools (Cursor, Claude Code) are coding agents. You’ll get significant leverage knowing what to ask for, recalling the right names and design patterns, and understanding what’s happening behind the scenes.
The workflow I use won’t work for those who vibe-code without understanding what the code does, how it should be structured, or whether it’s good code. The compounding effects of this workflow stem from the you * ai equation, not just because AI is smart.
I believe non-engineers can achieve similar or even better results using Lovable, n8n, and other tools. Here, I focus on developing software using code (still), ensuring that you and your organization remain in control of everything: tech stack, code, infrastructure, extendability.
Current Workflow Using Claude Code
My current workflow builds on the original workflow from Cursor with some important additions. Simply put, Claude Code enabled me to:
- Work on things in parallel.
- Run agents as long as they need to.
- Reduce my idle (waiting) time to almost zero.
- Get priority access to one of the best coding and reasoning models out there: Opus 4.
- Create my own development setup that helps me stay in the zone.
Let’s dive in.
Claude Code Basics
Claude Code is a command-line-based tool that works in your computer’s terminal. There are no buttons to press, the mouse doesn’t work here—the only interface is your keyboard. You use your terminal to navigate to your project’s directory, type claude, and you get the following interface.

What’s great about Claude Code is that you can open as many instances as you want. You could open one CC instance and ask it to analyse front-end code for potential race conditions when posting or fetching data from the backend and simultaneously open another instance to implement cookie notice in the project.
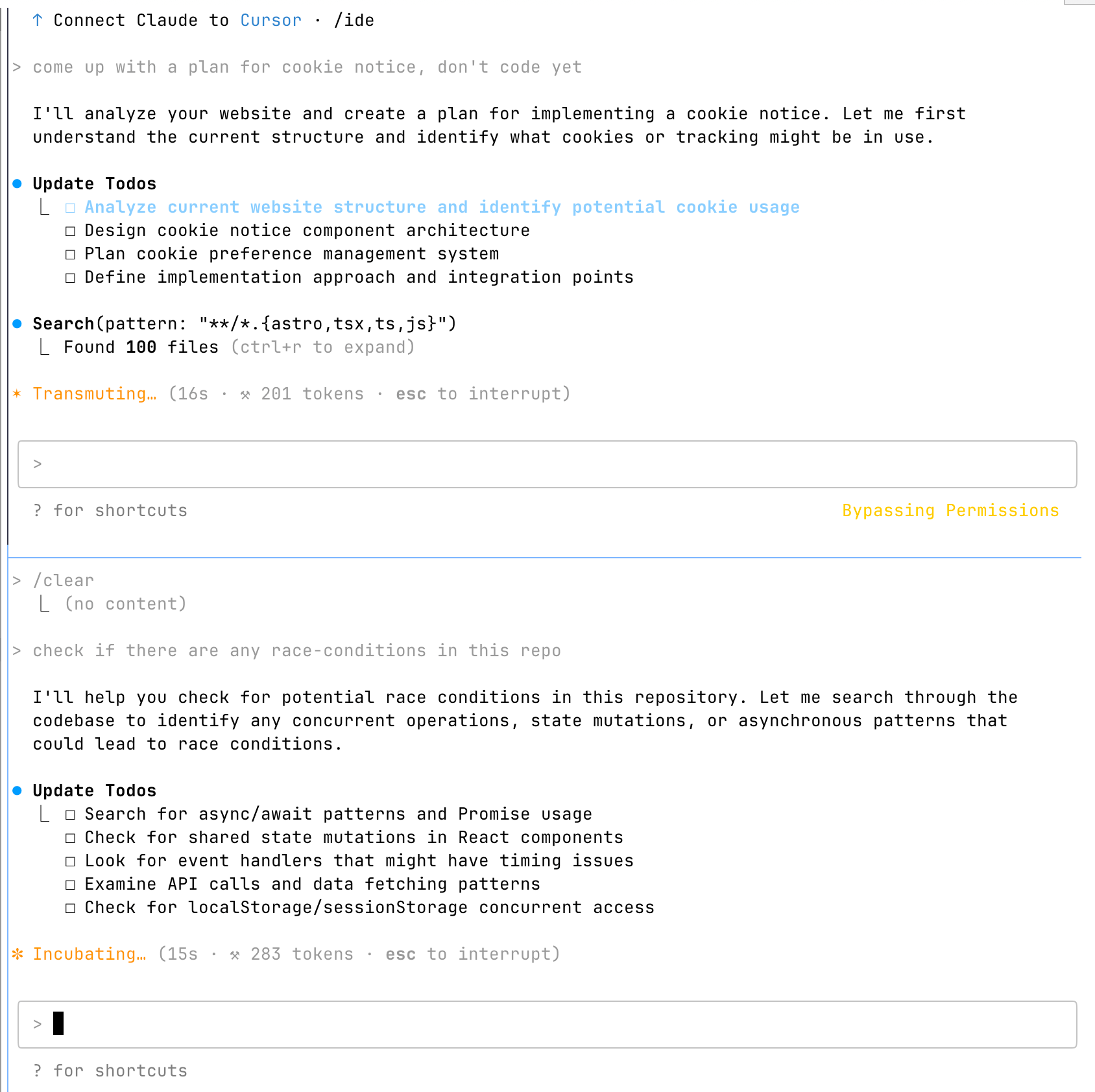
You can connect Claude Code to MCPs, giving it access to your database, web browsing capabilities (I use Puppeteer MCP), or task management (like Linear).
It’s worth noting that you can achieve both of these things in Cursor.
Once prompted, CC breaks tasks into internal todos and executes them sequentially. You can communicate with it while it’s working—messages are queued and processed between tool calls. This means you can redirect it when you see it going off track. You get full visibility into what’s happening behind the scenes.
Claude Code uses Sonnet 4 and Opus 4 under the hood. These models are happy to run for a long time. You can get a substantial amount of work done if you ask it to work on something you’ve both planned together beforehand. I’ve had it run for more than 6 hours in one go, conducting an audit of a mature codebase.
CC is evolving. Anthropic recently added subagents, which I’m still exploring and can’t say much about, apart from sensing a lot of hype out there (looking at you, YouTube influencers).
If you’re interested in subagents, I recommend checking this video by IndyDevDan. He made me realize that subagents are designed to report to the main agent, not me (the user). It’s the main agent who decides to use them and prompts them, not me. I misunderstood how they work, so I can’t say much about them yet. I’ll report back on this soon.
My Dev Setup
I’ve completely moved away from traditional IDEs like Cursor in favor of a terminal-based workflow. While this might sound extreme, it actually unlocks the kind of productivity I’m striving for. I can control everything I need with my keyboard. I can switch workspaces instantly, something that hasn’t been possible on Macs since Snow Leopard 💔 (DHH talks about this here).
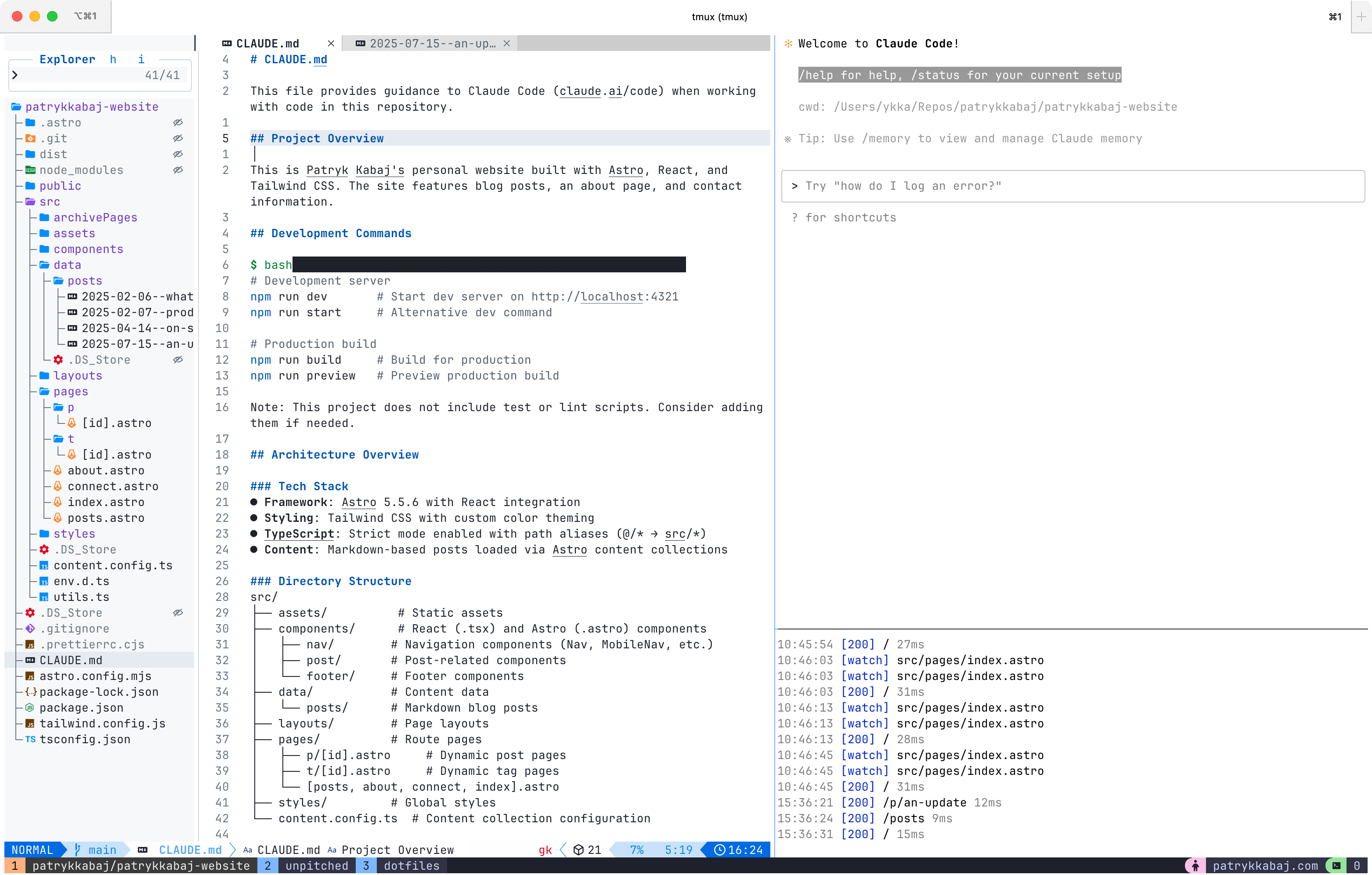
My stack consists of iTerm, Tmux, NeoVim, Linear, and Claude Code, all orchestrated through custom scripts and configurations. The magic happens in how these tools work together—I can spin up isolated development environments for each feature branch, complete with their own Claude Code instances, database connections, and dev servers.
The real advantage isn’t the tools themselves, but how they enable seamless context switching between multiple parallel workstreams. When I can jump between three different feature developments almost instantly, it keeps me in the zone and helps me get more done.
Running Claude Code
I use git worktrees to run Claude Code instances in parallel on separate branches in separate folders, preventing agents from editing the same files simultaneously. I have a script that creates a new git worktree (a separate folder for the entire repo on its own branch), copies gitignored files (environment variables, CC configs), and launches a new Tmux window with a complete dev environment ready to go (Vim, Claude Code, and servers running). Check this article by Tadas Antanavicius, co-creator of Pulse MCP—it explains the full setup.
I run Claude Code in Bypassing All Permissions mode, which carries risk. I’m transitioning all my work to a Docker-based or VPS-based setup to make this approach safer for autonomous operation.
Puppeteer and PostgreSQL MCP
Puppeteer is a software tool that acts like a “remote control” for web browsers. If you connect it as an MCP, models can navigate to sites, take screenshots, press buttons, type text into fields, and extract data from sites. This makes it possible for the model to test and debug its own work. The same goes for databases—you can enable the model to check what’s in the database.
I have Puppeteer and PostgreSQL connected via MCP to Claude Code and have had great success so far. If you provide CC with ways of testing its own implementation, it improves output quality by an order of magnitude.
Planning
I still rely on the original workflow. I create plans, save them, work off them, then convert them to documentation. I use Claude Code for that. However, I’ve extended that workflow with Linear.
I prioritize my work in Linear. I use Linear’s extension in Raycast to quickly save anything I don’t want to forget about, without ever leaving my current context and without opening Linear. For smaller fixes and tasks, I’ll open Linear, create a new issue, and use Aqua’s STT to describe what I need changed, fixed, or improved.
I have Linear connected to Claude Code as an MCP and have added a slash command to Claude Code that helps me analyze issues in Linear, research solutions, come up with a plan, and then work on it. The command is dead simple. I tried building more robust commands using markdown, but they all seemed to make Claude Code not behave like Claude Code.
Get the issue id:#$1 task from Linear and come up with a plan on how to implement it. You must not code yet.
Clarify any ambiguities by asking questions in the following format:
1. [Question about requirement/scope]
a. [Suggested answer option]
b. [Alternative answer option]
2. [Technical clarification question]
a. [Technical option A]
b. [Technical option B]Working In Parallel
Putting it all together, I have:
- A way to create a new dev environment, configured to a newly created feature/fix branch, located in a separate folder, with all tools open and ready to go.
- Robust plans co-developed with Claude Code and/or smaller self-explanatory issues in Linear.
- A way of switching context fast, with all tools available at my fingertips.
- Models able to test and debug their own implementation autonomously.
This setup, along with the original workflow, allows me to work on three, occasionally four tasks in parallel. I consider anything more than three tasks in parallel rather extreme. Typically, I’ll work on one difficult/complex task, one semi-complex task, and another chore or bug issue from Linear. I once tried running four tasks in parallel for a whole day and almost fried my brain by the end.
I work on them asynchronously. Whenever I have time and head space to launch another track in a separate workspace, I’ll do that. I don’t have any notifications configured to prompt me when they finish. I found this unnecessary, as I typically cycle through them from time to time to check on them. Sometimes, if I need to dive deep into some task or code review for one of the tracks, I’ll do so, not caring about the others waiting for me and not doing any work. Getting 100% out of what’s possible isn’t my goal - I’m probably at 90% of what I can sustain without going crazy.
Once I’m happy with the result, I’ll merge it back using git and run a script that cleans everything up for me.
Cost and Limits
I’m on the $200/month Claude Code Max plan. According to the CLI tool ccusage, I would have spent $1,505.12 in July alone if I was using it via API key. The $200/month may sound ridiculous at first, but when you realize how much can be accomplished thanks to it, it becomes clear that it’s a great deal.
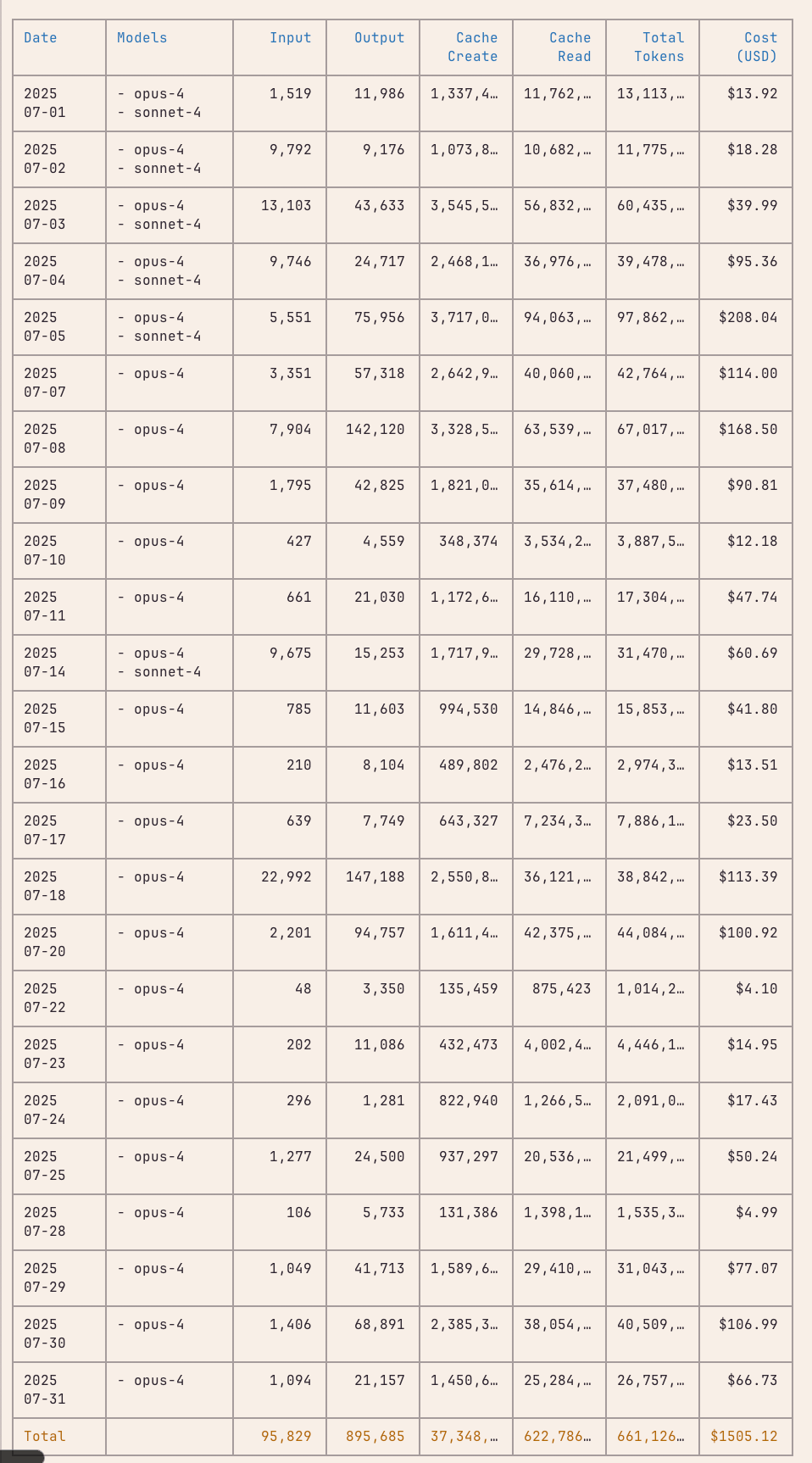
Personally, I haven’t run into limits on the $200/month Max plan lately. Sure, there were days when I would do (too) many things at once across multiple repositories, and I inevitably ran into limits. I’d say the limits on the $200/month plan are fine.
How Good Is It?
Here are some examples of what I was able to achieve and in how many hours (including planning), so you can judge for yourself. All of them relied on the workflow and dev setup I outlined here today.
- An app that extracts book authors and titles from pictures of book spines, DVDs, and audio CDs, then scrapes online second-hand bookshops and marketplaces to get their potential prices, stores it all in an SQLite database, and presents it in a simple web-based UI —
8h. - A feedback form in Unpitched, with client-side and server-side validations, robust error-handling, product instrumentation, background job via third-party integration trigger.dev and Resend. No mistakes made by the model, only a config issue on my end —
40 min. - Refactor of the entire Unpitched codebase introducing shared server and client-side validations using Zod —
3h. - PostHog Product Instrumentation for Unpitched, introducing ~20 events with payloads —
3h.
To give you an idea, Unpitched is 24,000 lines of code, and I reduced it by a few thousand lines toward launch. The timings reflect the time needed from the moment I began working until I had it done, tested, and pushed to production.
Wrapping Up
Claude Code was an inflection point for me. It enabled me to parallelize work and speed it up anywhere from 1.5x to 4x faster. This depends on the task at hand, but I’ve been able to build features that would have taken me days in just a couple of hours. Perhaps this will convince you: I’m not ashamed of the code produced as a result. It’s solid.
It may come as a surprise, but I’m familiar with all the code generated this way. I used to skip the review part and quickly regretted it. The point I’m making is that code review isn’t just a safety measure—it’s what allows you to elevate your work to a different level. When you maintain solid review practices while coding with agents, over time you begin to understand what works and what doesn’t. You become better at prompting, providing context, organizing work, and parallelizing it. It takes time to develop these skills. It doesn’t come free.
I highly encourage everyone to give it a go. Tip: start with a small scope and build on top of it. Documentation has become essential in this workflow.
Two posts are coming soon: a technical deep-dive into exactly how I’ve set all this up (scripts, configurations, the whole setup), and an analysis of what actually drives Claude Code costs.
If you want to get notified about them, please subscribe at Substack.
Thanks for reading!
References
-
How to use Claude Code to wield coding agent clusters by Tadas Antanavicius — Comprehensive guide on setting up git worktrees and parallel Claude Code instances that I reference in this post.
-
Claude Code: How Two Engineers Ship Like a Team of 15 — Team at Every on how they figured out how to unlock the potential of AI using Claude Code.
-
Agentic Engineering in Action with Mitchell Hashimoto — Mitchell Hasimoto, co-founder of HashiCorp and author of Ghostty, explains his AI engineering workflow.
-
claudelog.com — An excellent guide explaining how Claude Code works and how to set it up.
-
ccusage — Useful tool for tracking and analyzing your Claude Code usage patterns and costs.
-
How I Use Claude Code by Tyler Burnam — Another developer’s perspective on integrating Claude Code into their workflow.
-
I shipped a macOS app built entirely by Claude Code by Indragie Karunaratne — Fascinating case study of building a complete macOS application using Claude Code.
-
DHH on Mac workspace switching — DHH explains the frustration with Mac’s workspace switching limitations since Snow Leopard.
-
IndyDevDan on Claude Code subagents — Great explanation of how Claude subagents actually work.